
UNLE⛧SH THE BEAST ト何ゼ
| [MENU] | |||||||||
| [THOUGHTS] | [TECH RESOURCES] | [TRASH TALK] | |||||||
| [DANK MEMES] | [FEATURED ARTISTS] | [W] | |||||||
Setup a YARA Scanner in AWS Lambda
Oct. 3, 2022 // theatha
Introduction
Hello everyone! I've been searching how AWS Lambda can be used for analyzing things for a while. So I could get a YARA Scanner that could work on the remote server without messing with the server side and it's environment. I will explain how I setup a simple YARA Scanner in AWS Lambda in this blog. If you want to discuss or ask me something, you can reach me from twitter.
What is AWS Lambda?
Lambda is a compute service that lets you run code without provisioning or managing servers. Lambda runs your code on a high-availability compute infrastructure and performs all of the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, and logging. With Lambda, you can run code for virtually any type of application or backend service. Check the docs for more information.
Structure
The diagram of the structure is given below.
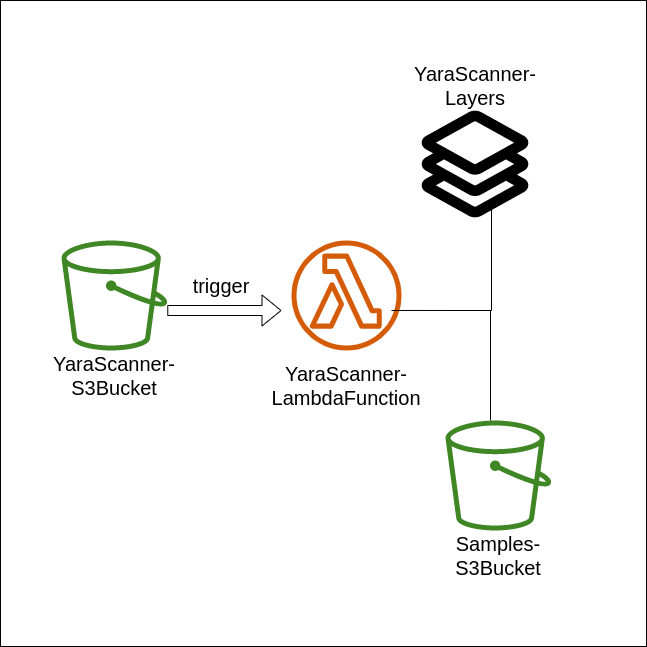
Trigger
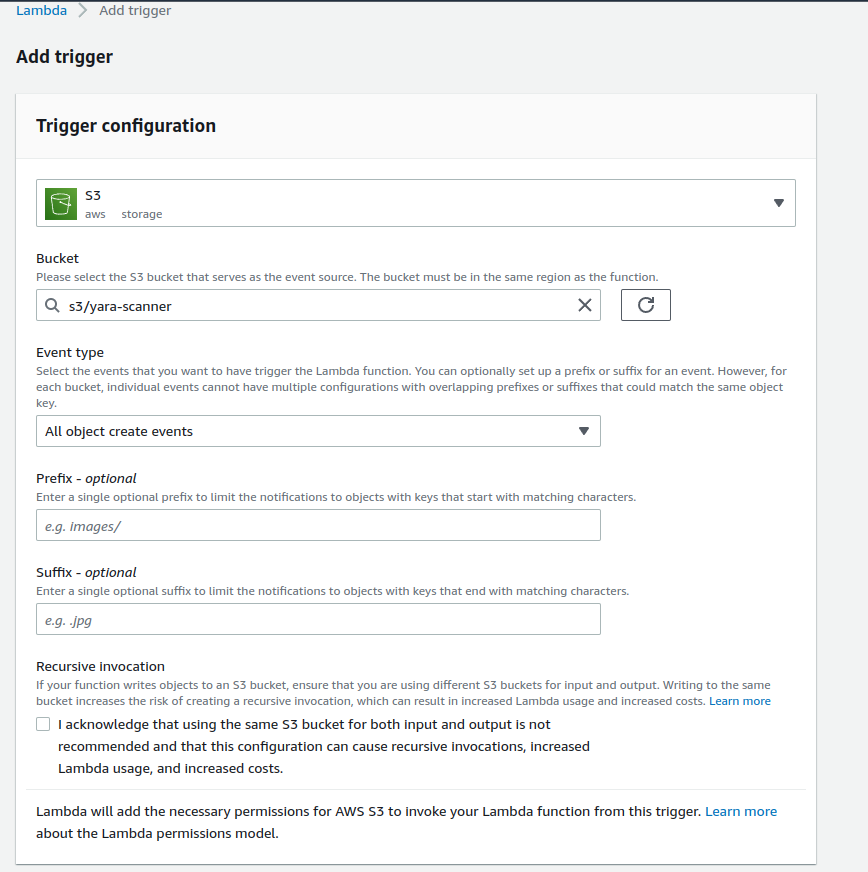
The AWS Lambda function must have a trigger. So, I used an S3 bucket as a trigger. Thus, the uploaded binary will trigger the lambda function. Also, you can use different AWS services as trigger. Check the docs for more information.
Layers
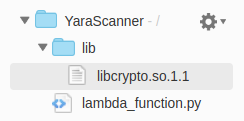
If a library other than standard libraries will be used, it must be added under Layers. I added all packages under the layers section for I used the "YARA" library.
Lambda Function
I preferred Python for the lambda function.
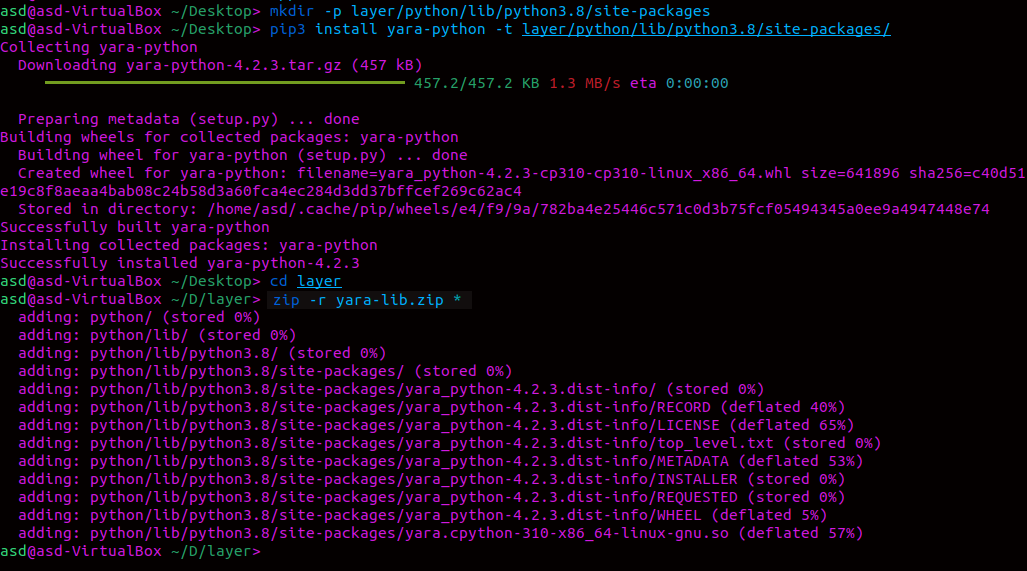
Installing YARA Package under Layers Section
The "YARA" library is not one of the standard libraries. So, all packages belonging to the "Yara" library must be added to the layers section.
- mkdir -p layer/python/lib/python3.8/site-packages/
- pip3 install yara-python -t layer/python/lib/python3.8/site-packages/
- cd layer
- zip -r yara-lib.zip *
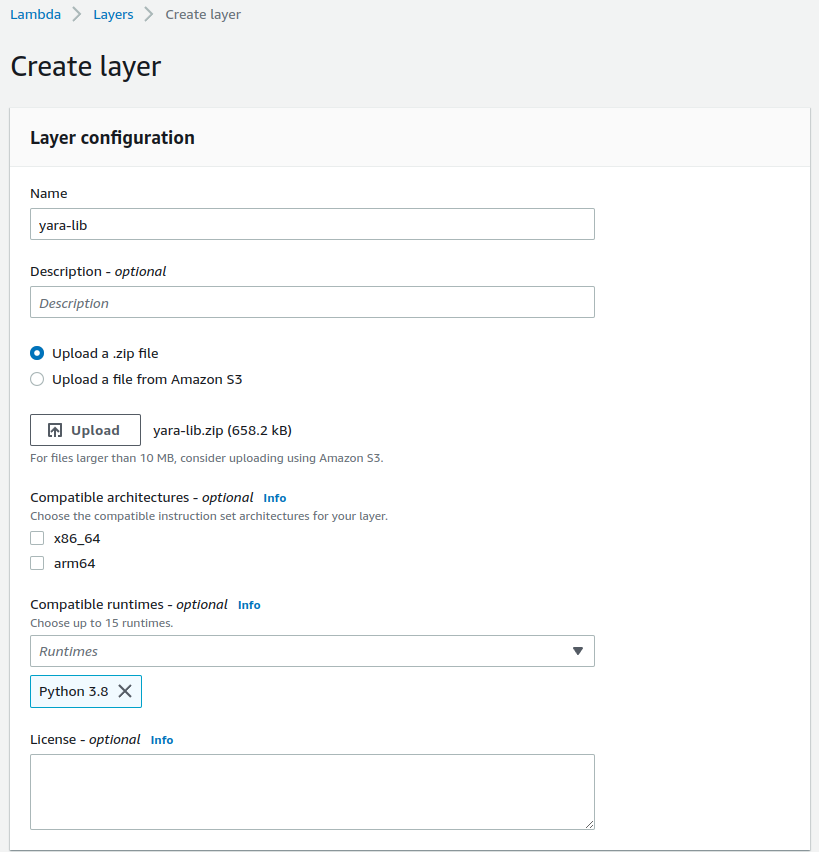
A new layer is created by uploading the zip file and added to the lambda function.
However, this is not enough for the "YARA" library to work correctly. Here is the screenshot of log.
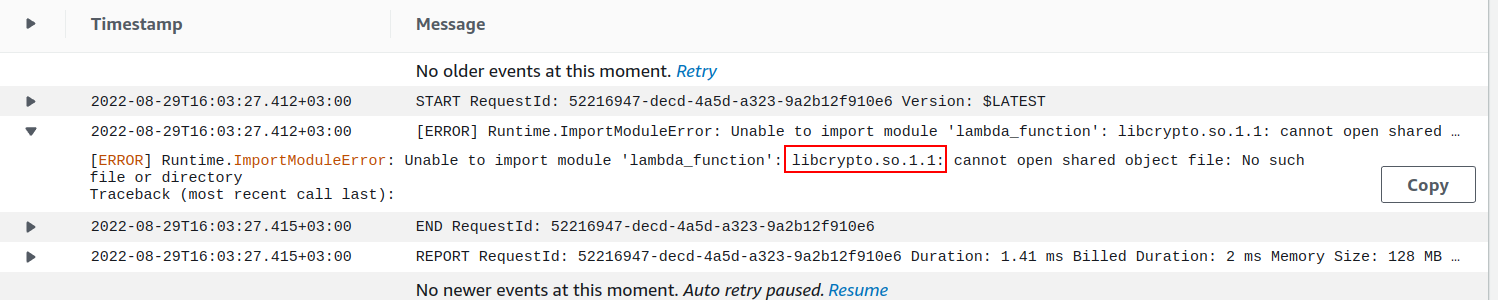
For solution, libcrypto.1.1.so file must be added to lib/ directory under code source.
S3 Bucket as a Trigger
After the S3 bucket is created, it can be added as a trigger.
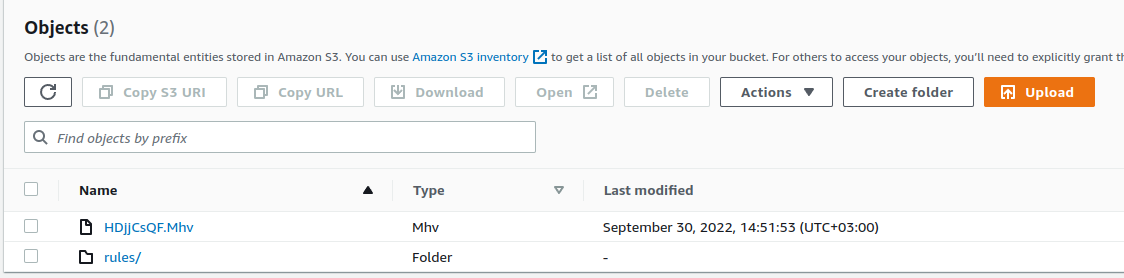
There is the rules directory and a malicious sample for scanning in the S3 bucket.
 Policies, Permissions
Policies, Permissions
In order to both download and list files from S3 Bucket, the given Policy file needs to be edited.
- {
- "Sid": "VisualEditor1",
- "Effect": "Allow",
- "Action": [
- "s3:GetObject",
- "s3:ListBucket",
- "logs:CreateLogGroup"
- ],
- "Resource": [
- "arn:aws:s3:::*/*"
- ]
- }
Lambda Function
I will explain the yara scanner code step by step. Importing related libraries.
- import yara
- import boto3
Adding it as a client because the S3 bucket will be used.
- s3_client = boto3.client("s3")
The triggered function is the lambda_handler function. For this reason, the desired operations must be written under this function.
- def lambda_handler(event, context):
Getting the names of yara rule files.
- # continued
- bucket_name = "<bucketname>"
- response = s3_client.list_objects_v2(Bucket=bucket_name)
- rule_list = []
- for content in response['Contents']:
- if content['Key'].startswith('rules'):
- rule_list.append(content['Key'])
-
- rule_list.pop(0)
- print("rules: " , rule_list)
Reading the file uploaded to S3 Bucket.
- # continued
- uploaded_file = event['Records'][0]['s3']['object']['key']
- print('Uploaded file: ', uploaded_file)
- response = s3_client.get_object(Bucket=bucket_name, Key=uploaded_file)
- uploaded_binary = response['Body'].read()
Compiling and running the yara rules on the uploaded file and outputting the match results.
- # continued
- match_status = []
- for i in rule_list:
- response = s3_client.get_object(Bucket=bucket_name, Key=i)
- data = response['Body'].read().decode('utf-8')
- rule = yara.compile(source=data)
- matches = rule.match(data=uploaded_binary)
- #print(matches)
- if not matches:
- match_status.append(f"{i} did not match {uploaded_file}")
-
- else:
- match_status.append(f"{i} matched {uploaded_file}")
- print(match_status)
CloudWatch
CloudWatch was used for output. The following image shows the output after a file has been uploaded.

The Conclusion
A simple Yara Scanner was made with AWS Lambda. I like AWS Lambda because it's pretty simple and anything can be done easily. You can find source codes, lib, and python packages in "this" repo.