
UNLE⛧SH THE BEAST ト何ゼ
| [MENU] | |||||||||
| [THOUGHTS] | [TECH RESOURCES] | [TRASH TALK] | |||||||
| [DANK MEMES] | [FEATURED ARTISTS] | [W] | |||||||
How to understand dirtyCOW vulnerability
April 12, 2021 // echel0n
How to understand DirtyCOW Vulnerability
Hello guys! I was studying linux kernel vulnerabilities and decided to examine dirtyCOW vulnerability.
I thought it will be helpful to other people that interested in kernel vulnerabilities.
There are some good references to read before deep dive in how dirtyCOW vulnerability occurs.
It is possible to say it's a dirtyCOW write-up write-up. (smile was here)
Hope you will enjoy!
Also this guide is inspired and referenced by the following blog posts.
Dirty COW and why lying is bad even if you are the Linux KerneldirtyCOW Vulnerability Details
Table of Content;
- *) (Memory Management)
- * (Virtual Memory)
- * (Virtual Memory Areas)
- * (Pages, Page Tables, Paging, Page Faults)
- *) madvise()
- *) Linux psuedo files
- *) Concurrent programming and vulnerabilities due to race conditions
If you already know these subjects what is about, this blog will not help you so much.
Intro
DirtyCOW vulnerability causes a user with limited privileges to write permissions for memory areas that are actually given only read rights by linux kernel. Also, It means this will allow overwrite files on the disk, bypassing standart authorization mechanisms. We will get to there but we have to understand how kernel handles the data and how manages memory firstly.
Lets get started with the name of vulnerability dirty and COW. Which are playing the role in naming of it. This would be a good step to slightly open the veils of mystery for this vulnerability.
Dirty
If some data is written, it is firstly written to the page cache and this data is managed as one of the dirty pages. Dirty indicates that this data is written to page caching but this data should be written to storage sometime. The contents of these dirty pages are periodically transferred (via sync and fsync) to storage devices. This storage device can be a RAID controller or a hard disk.
As an example, it is possible to discover this feature in the command line.
With the help of dd command, (or just copy paste and save a text file, we have plentiful choices to write) let's create a 10MB file in a directory.
- $ dd if=/dev/zero of=sample.txt bs=1M count=10
- 10+0 records in
- 10+0 records out
- 10485760 bytes (10 MB, 10 MiB) copied, 0.0209083 s, 502 MB/s
At this point, this output indicates that it is now written to the page cache and next sync period will be directly written to the hard disk. We can check the size of dirty pages with the following commands.
- $ cat /proc/meminfo | grep Dirty
- Dirty: 548 kB
Maybe because I could not capture all of this periodic time because I am using SSD as a storage device and the data is instantly written on the disk because it was only 10MB. Let's try with bigger input.
- $ dd if=/dev/urandom of=sample.txt bs=1M count=1024
- ^C392+0 records in
- 391+0 records out
- 409993216 bytes (410 MB, 391 MiB) copied, 5.84164 s, 70.2 MB/s
At this point, i am expecting that, it will fall behind and will create dirty pages. Let's try that again.
- $ grep Dirty /proc/meminfo
- Dirty: 72628 kB
- $ grep Dirty /proc/meminfo
- Dirty: 104380 kB
- $ grep Dirty /proc/meminfo
- Dirty: 171856 kB
- # We can wait synchronization period time or we can manually do that synchronization with sync command
- $ sync
- $ cat /proc/meminfo | grep Dirty
- Dirty: 0 kB
The important thing for us was to understand how page cache and dirty pages work somehow and we have seen it.
The 10MB example is from this website.
Copy-on-Write (COW)
Copy-on-write (sometimes referred to as "COW") is an optimization strategy used in computer programming. The fundamental idea is that if multiple callers ask for resources which are initially indistinguishable, you can give them pointers to the same resource. This function can be maintained until a caller tries to modify its "copy" of the resource, at which point a true private copy is created to prevent the changes becoming visible to everyone else. All of this happens transparently to the callers. The primary advantage is that if a caller never makes any modifications, no private copy need ever be created.
Original post on stackoverflowADHD version of COW explanation
- Process:P
- Proccesses:Ps
- Kernel:K
-
- Ps: we want the same resource!!
- K: Yeah take it *gives pointers that points to the same resource*
- P: I loved it, I would like to change it, *tries to write some data*
- K: *inserts 'we dont do that here' meme*
- P: uWu
- K: *Creates a private copy*
- K: *Slaps roof of newly created private copy*
- K: This copy can fit so many data inside of it.
So, we have a little knowledge about the mechanisms of it somehow. But we need to go deeper than that.
Virtual Memory
(Taken from SearchStorage)Virtual memory uses both computer hardware and software to work. When an application is in use, data from that program is stored in a physical address using RAM. More specifically, virtual memory will map that address to RAM using a memory management unit (MMU). The OS will make and manage memory mappings by using page tables and other data structures. The MMU, which acts as an address translation hardware, will automatically translate the addresses.
If at any point later the RAM space is needed for something more urgent, the data can be swapped out of RAM and into virtual memory. The computer's memory manager is in charge of keeping track of the shifts between physical and virtual memory. If that data is needed again, a context switch can be used to resume execution again.
While copying virtual memory into physical memory, the OS divides memory into pagefiles or swap files with a fixed number of addresses. Each page is stored on a disk, and when the page is needed, the OS copies it from the disk to main memory and translates the virtual addresses into real addresses.
(Taken from Wikipedia)
Virtual memory makes application programming easier by hiding fragmentation of physical memory; by delegating to the kernel the burden of managing the memory hierarchy (eliminating the need for the program to handle overlays expcilitly); and when each process is run in its own dedicated address space, by obviating the need to relocate program code or to access memory with relative addressing.
Lets look at /proc/iomem/ with root permissions. My device has 16GB RAM. RAM Buffer looks like this on my device.
- 00001000-0009dfff : System RAM
- 0009f000-0009ffff : System RAM
- 00100000-3fffffff : System RAM
- 40400000-6db76017 : System RAM
- 6db76018-6db86057 : System RAM
- 6db86058-6db87017 : System RAM
- 6db87018-6db95857 : System RAM
- 6db95858-70775fff : System RAM
- 70778000-73972fff : System RAM
- 739fc000-78091fff : System RAM
- 790fe000-790fefff : System RAM
- 100000000-47e7fffff : System RAM
- 47e800000-47fffffff : RAM buffer
When we calculate this upper value like this;
- >>> 0x47fffffff/1024/1024/1024
- 17.999999999068677
It seems buffer is nearly 18GB. At this point, I don't know why it indicates that 18GB while it has only 16GB RAM. I am also learning while I am writing this post too.
EDIT: After asking this confusion about RAM Buffer value to @lntrx, he explained that this value indicates the mappable area. This value is not related with RAM size. The value shows how many area that can be virtually mapped.
Are you hearing cracking sounds in your head? Good. hbmap() is called.
- $ man hbmap
- human brain memory allocation
- creates a memory area when it is needed
- side effects: feeling low, glowing eyes, feels like the back of person head is on fire
In the first part of this page ,CPU and DMA addresses section shows a nice example of how it works. This sample of the first section is really helpful;
The kernel normally uses virtual addresses. The virtual memory system (TLB, page tables, etc.) translates virtual addresses to CPU physical addresses, which are stored as phys_addr_t` or `resource_size_t`. The kernel manages device resources like registers as physical addresses. These are the addresses in /proc/iomem. The physical address is not directly useful to a driver; it must use ioremap() to map the space and produce a virtual address.
Virtual Memory Areas
(Taken from O'REILLY)
The kernel uses virtual memory areas to keep track of the process's memory mappings; for example, a process has one VMA for its code, one VMA for each type of data, one VMA for each distinct memory mapping (if any), and so on. VMAs are processor-independent structures, with permissions and access control flags. Each VMA has a start address, a length and their sizes are always a multiple of the page size (PAGE_SIZE). A VMA consists of a number of pages, each of which has an entry in the page table.
Memory regions described by VMA are always virtually contiguous, not physically. You can check all VMAs associated with a process through the /proc/pid/maps file, or using the pmap command on a process ID.
Lets do some examples;- Usage:
- pmap [options] PID [PID ...]
-
- Options:
- -x, --extended show details
- -X show even more details
- WARNING: format changes according to /proc/PID/smaps
- -XX show everything the kernel provides
- -c, --read-rc read the default rc
- -C, --read-rc-from=<file> read the rc from file
- -n, --create-rc create new default rc
- -N, --create-rc-to=<file> create new rc to file
- NOTE: pid arguments are not allowed with -n, -N
- -d, --device show the device format
- -q, --quiet do not display header and footer
- -p, --show-path show path in the mapping
- -A, --range=<low>[,<high>] limit results to the given range
-
- -h, --help display this help and exit
- -V, --version output version information and exit
-
- For more details see pmap(1).
- </high></low></file></file>
I did ps auxwww| grep -i alacritty and got my target PID (ex: 14586) A lot of addresses and resources came up like TTF files, libnss_files.so, libGLX_mesa.so and ld.so etc etc. The description also says that we can use /proc/pid/maps file let's cat that file and see what is going on there.
- .
- .
- .
- .
-
- 7fcf09f9e000-7fcf0a0c5000 r--s 00000000 103:02 1704785 /var/cache/fontconfig/f6b893a7224233d96cb72fd88691c0b4-le64.cache-7
- 7fcf0a0c5000-7fcf0a139000 rw-p 00000000 00:00 0
- 7fcf0a139000-7fcf0a13a000 r--p 00000000 103:02 153721 /usr/lib/libxcb-present.so.0.0.0
- 7fcf0a13a000-7fcf0a13b000 r-xp 00001000 103:02 153721 /usr/lib/libxcb-present.so.0.0.0
- 7fcf0a13b000-7fcf0a13c000 r--p 00002000 103:02 153721 /usr/lib/libxcb-present.so.0.0.0
- 7fcf0a13c000-7fcf0a13d000 r--p 00002000 103:02 153721 /usr/lib/libxcb-present.so.0.0.0
- 7fcf0a13d000-7fcf0a13e000 rw-p 00003000 103:02 153721 /usr/lib/libxcb-present.so.0.0.0
- 7fcf0a13e000-7fcf0a140000 r--p 00000000 103:02 153715 /usr/lib/libxcb-dri3.so.0.0.0
- 7fcf0a140000-7fcf0a141000 r-xp 00002000 103:02 153715 /usr/lib/libxcb-dri3.so.0.0.0
- 7fcf0a141000-7fcf0a142000 r--p 00003000 103:02 153715 /usr/lib/libxcb-dri3.so.0.0.0
- 7fcf0a142000-7fcf0a143000 r--p 00003000 103:02 153715 /usr/lib/libxcb-dri3.so.0.0.0
- 7fcf0a143000-7fcf0a144000 rw-p 00004000 103:02 153715 /usr/lib/libxcb-dri3.so.0.0.0
- 7fcf0a144000-7fcf0a145000 r--p 00000000 103:02 153742 /usr/lib/libxcb-shm.so.0.0.0
- 7fcf0a145000-7fcf0a146000 r-xp 00001000 103:02 153742 /usr/lib/libxcb-shm.so.0.0.0
- 7fcf0a146000-7fcf0a147000 r--p 00002000 103:02 153742 /usr/lib/libxcb-shm.so.0.0.0
- 7fcf0a147000-7fcf0a148000 r--p 00002000 103:02 153742 /usr/lib/libxcb-shm.so.0.0.0
- 7fcf0a148000-7fcf0a149000 rw-p 00003000 103:02 153742 /usr/lib/libxcb-shm.so.0.0.0
- 7fcf0a149000-7fcf0a14a000 r--p 00000000 103:02 157816 /usr/lib/libXxf86vm.so.1.0.0
- 7fcf0a14a000-7fcf0a14d000 r-xp 00001000 103:02 157816 /usr/lib/libXxf86vm.so.1.0.0
- 7fcf0a14d000-7fcf0a14e000 r--p 00004000 103:02 157816 /usr/lib/libXxf86vm.so.1.0.0
- 7fcf0a14e000-7fcf0a14f000 r--p 00004000 103:02 157816 /usr/lib/libXxf86vm.so.1.0.0
- 7fcf0a14f000-7fcf0a150000 rw-p 00005000 103:02 157816 /usr/lib/libXxf86vm.so.1.0.0
- 7fcf0a150000-7fcf0a151000 r--p 00000000 103:02 157492 /usr/lib/libXdamage.so.1.1.0
- 7fcf0a151000-7fcf0a152000 r-xp 00001000 103:02 157492 /usr/lib/libXdamage.so.1.1.0
- 7fcf0a152000-7fcf0a153000 r--p 00002000 103:02 157492 /usr/lib/libXdamage.so.1.1.0
- 7fcf0a153000-7fcf0a154000 r--p 00002000 103:02 157492 /usr/lib/libXdamage.so.1.1.0
- 7fcf0a154000-7fcf0a155000 rw-p 00003000 103:02 157492 /usr/lib/libXdamage.so.1.1.0
- 7fcf0a155000-7fcf0a15a000 r--p 00000000 103:02 157785 /usr/lib/libdrm.so.2.4.0
- 7fcf0a15a000-7fcf0a164000 r-xp 00005000 103:02 157785 /usr/lib/libdrm.so.2.4.0
- 7fcf0a164000-7fcf0a168000 r--p 0000f000 103:02 157785 /usr/lib/libdrm.so.2.4.0
- 7fcf0a168000-7fcf0a169000 r--p 00012000 103:02 157785 /usr/lib/libdrm.so.2.4.0
- 7fcf0a169000-7fcf0a16a000 rw-p 00013000 103:02 157785 /usr/lib/libdrm.so.2.4.0
- 7fcf0a16a000-7fcf0a1ac000 r--p 00000000 103:02 158011 /usr/lib/libGL.so.1.7.0
- 7fcf0a1ac000-7fcf0a1cb000 r-xp 00042000 103:02 158011 /usr/lib/libGL.so.1.7.0
- 7fcf0a1cb000-7fcf0a1e0000 r--p 00061000 103:02 158011 /usr/lib/libGL.so.1.7.0
- 7fcf0a1e0000-7fcf0a1ee000 r--p 00075000 103:02 158011 /usr/lib/libGL.so.1.7.0
- 7fcf0a1ee000-7fcf0a1ef000 rw-p 00083000 103:02 158011 /usr/lib/libGL.so.1.7.0
- 7fcf0a1ef000-7fcf0a1f0000 rw-p 00000000 00:00 0
- 7fcf0a1f3000-7fcf0a1f4000 rw-s 00000000 00:01 30160 /memfd:xshmfence (deleted)
- 7fcf0a1f4000-7fcf0a1f5000 rw-s 100331000 00:0d 11020 anon_inode:i915.gem
- 7fcf0a1f5000-7fcf0a1f6000 rw-s 10148a000 00:0d 11020 anon_inode:i915.gem
- 7fcf0a1f6000-7fcf0a1fa000 rw-s 101446000 00:0d 11020 anon_inode:i915.gem
- 7fcf0a1fa000-7fcf0a20a000 rw-s 100bc9000 00:0d 11020 anon_inode:i915.gem
- 7fcf0a20a000-7fcf0a21e000 r--s 00000000 103:02 1704794 /var/cache/fontconfig/614d1caaa4d7914789410f6367de37ca-le64.cache-7
- 7fcf0a21e000-7fcf0a505000 r--p 00000000 103:02 169046 /usr/lib/locale/locale-archive
-
- .
- .
- .
- .
- .
- .
It also shows the same information about mapping but more detailed from default informations and also shows full path of binaries and other resources too. Also worth to mention, the information about -X option in pmap output "(WARNING: format changes according to /proc/PID/smaps)", the mentioned file is came to my attention, when i check that file, the example output is like this;
- 7fcf0aeab000-7fcf0aeac000 rw-p 00007000 103:02 157097 /usr/lib/libXfixes.so.3.1.0
- Size: 4 kB
- KernelPageSize: 4 kB
- MMUPageSize: 4 kB
- Rss: 4 kB
- Pss: 4 kB
- Shared_Clean: 0 kB
- Shared_Dirty: 0 kB
- Private_Clean: 0 kB
- Private_Dirty: 4 kB
- Referenced: 4 kB
- Anonymous: 4 kB
- LazyFree: 0 kB
- AnonHugePages: 0 kB
- ShmemPmdMapped: 0 kB
- FilePmdMapped: 0 kB
- Shared_Hugetlb: 0 kB
- Private_Hugetlb: 0 kB
- Swap: 0 kB
- SwapPss: 0 kB
- Locked: 0 kB
- THPeligible: 0
- VmFlags: rd wr mr mw me ac sd
Yeah, we know some of these words...
Pages, Page Tables and Paging
We covered a lot stuff about Virtual Memory and Memory Areas, copy-on-write subjects. While we are reading these concepts, nearly every subject, Page is mentioned. But! What is a Page actually?
(Taken from Wikipedia)
In computer operating systems, memory paging is a memory management scheme by which a computer stores and retrieves data from secondary storage for use in main memory. In this scheme, the operating system retrieves data from secondary storage in same-size blocks called pages. Paging is an important part of virtual memory implementations in modern operating system, using secondary storage to let program exceed the size of available physical memory.
Let's say this main memory is "RAM" and the storage is "hard disk". We can assume this for simplicity but this concepts do not depend on whether these terms apply literally to a specific computer system.
A page, memory page or virtual page is a fixed length contiguous block of virtual memory, described by a single entry in the page table. It is the smallest unit of data for memory management in a virtual memory operating system. Similarly, a page frame is the smallest fixed-length contiguous block of physical memory into which memory pages are mapped by the operating system.
Monitoring Virtual Memory with vmstat, Taken from hereTLDR;Paging refers to writing portions, termed pages, of a process memory to disk. Not to confuse with swapping; Swapping, strictly speaking, refers to writing the entire process, not just part, to disk.
One mystery came to my mind, some command line operations do not work when I run out of space(nearly %100) on the hard disk even it does nothing related with storage. It gives some error and exits. Is it related to that? If you know the answer can you write me a message from twitter or telegram?
Page Tables
A page table is the data structure used by a virtual memory system in a computer operating system to store the mapping between virtual addresses and physical addresses. Virtual addresses are used by the program executed by the accessing process, while physical addresses are used by the hardware, or more specifically, by the RAM subsystem.
(Taken from TLDP)
TLDP | Chapter 3 Memory Management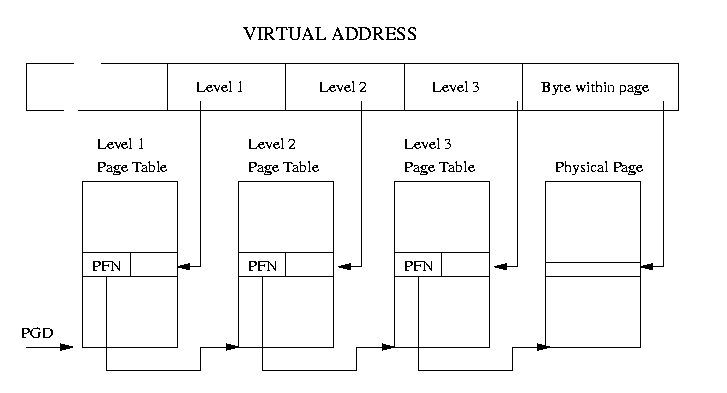
Linux assumes that there are three levels of page tables. Each Page Table accessed contains the page frame number of the next level of Page Table. Figure 3.3 shows how a virtual address can be broken into a number of fields; each field providing an offset into a particular Page Table. To translate a virtual address into a physical one, the processor must take the contents of each level field, convert it into an offset into the physical page containing the Page Table and read the page frame number of the next level of Page Table. This is repeated three times until the page frame number of the physical page containing the virtual address is found. Now the final field in the virtual address, the byte offset, is used to find the data inside the page. Each platform that Linux runs on must provide translation macros that allow the kernel to traverse the page tables for a particular process. This way, the kernel does not need to know the format of the page table entries or how they are arranged. This is so successful that Linux uses the same page table manipulation code for the Alpha processor, which has three levels of page tables, and for Intel x86 processors, which have two levels of page tables.
Page Faults
Taken from cyberciti.bizLinux (and most Unix like) system uses a virtual memory into a physical address space. Linux kernel manages this mapping as and when required using “on demand” technique. A page fault occurs when a process accesses a page that is mapped in the virtual address space, but not loaded in physical memory. In most cases, page faults are not errors. They are used to increase the amount of memory available to programs in Linux and Unix like operating systems that use virtual memory. Virtual memory is nothing but a memory management technique used by Linux and many other modern operating systems that combine active RAM and inactive memory on the disk drive (hard disk / ssd) to form a large range of contiguous addresses.
Page Fault Types & Examples
- 1. A major fault occurs when disk access required.
- For example; let's start Firefox Browser.
- The Linux kernel will search in the physical memory and CPU cache.
- If data do not exist, the Linux issues a major page fault.
-
- 2. A minor fault occurs due to page allocation.
The easiest way to remember the difference is:
Minor page faults can be served from existing virtual memory,
while major page faults have to request more pages be allocated from the physical memory.
Viewing Page Faults
- # min_flt: number of minor page faults.
- # maj_flt: number of major page faults.
- # `pgrep alacritty`: PID
- $ ps -o min_flt, maj_flt `pgrep alacritty`
- MINFL MAJFL
- 9662 4
Page Fault Types
If you would like to check out all page fault types,
you can check out linux memory management source code.
It is located at linux/mm.h line: 424
- piece of definitions
- /*
- ....
- * @FAULT_FLAG_WRITE: Fault was a write fault.
- * @FAULT_FLAG_MKWRITE: Fault was mkwrite of existing PTE.
- * @FAULT_FLAG_ALLOW_RETRY: Allow to retry the fault if blocked.
- * @FAULT_FLAG_RETRY_NOWAIT: Don't drop mmap_lock and wait when retrying.
- * @FAULT_FLAG_KILLABLE: The fault task is in SIGKILL killable region.
- * @FAULT_FLAG_TRIED: The fault has been tried once.
- * @FAULT_FLAG_USER: The fault originated in userspace.
- * @FAULT_FLAG_REMOTE: The fault is not for current task/mm.
- * @FAULT_FLAG_INSTRUCTION: The fault was during an instruction fetch.
- * @FAULT_FLAG_INTERRUPTIBLE: The fault can be interrupted by non-fatal signals.
- ...
- */
Also worth to mention, you will see dirtyCOW patch includes a flag named FOLL_COW, if you would like to check these flags yourself and explanations they are in include/linux/mm.h line: 2275
newest mm.h github link
madvise(2) system call
The comments are explaining clearly what it does and it's behaviour
madvise.c github link line: 993
- /*
- * The madvise(2) system call.
- *
- * Applications can use madvise() to advise the kernel how it should
- * handle paging I/O in this VM area. The idea is to help the kernel
- * use appropriate read-ahead and caching techniques. The information
- * provided is advisory only, and can be safely disregarded by the
- * kernel without affecting the correct operation of the application.
- ...
- * MADV_DONTNEED - the application is finished with the given range,
- * so the kernel can free resources associated with it.
- ...
- */
The commented lines are descriptive enough. While we are calling madvise() syscall from another thread, we are advising to kernel "i am done with this page and you can free this resource, if you want to."
Linux psuedo files simply explained
Taken from superuser.com
Original replies here- (Second answer)
- this information does not persist across reboots.
- It exists while the system in running only in RAM;
- in Windows this would be the 'HKLM'
- in linux /dev this includes things like '/dev/tty#' '/dev/ttyS#'
- they indicate devices as they are connected and they can be created dynamically.
- '/sys' shows a representation of the physical devices in the machine
- '/proc' maintain a lot of info about the current control set
- example; 'free' command is just importing info from '/proc/meminfo' file.
Concurrent programming and race conditions
I will just leave the links here as I cannot explain it better than the wikipedia entries, I am sorry... :'(
Check specifically 'Coordinating access to shared resources'Race condition Wikipedia page
In conclusion, these subjects and links are helping me on the way of understanding dirtyCOW vulnerability and how memory management is done in linux.
The vulnerability is pretty old and patched already a long time ago but
it was very difficult for me to understand and study the vulnerability.
If you would like to add something in this blog please reach me on twitter, I would like to discuss and learn more.
Think that you have studied enough these, you are ready to read some write-up about it!