UNLE⛧SH THE BEAST ト何ゼ
| [MENU] | |||||||||
| [THOUGHTS] | [TECH RESOURCES] | [TRASH TALK] | |||||||
| [DANK MEMES] | [FEATURED ARTISTS] | [W] | |||||||
Brainflow: More like BrainOverflow
July 29, 2022 // echel0n
BrainFlow: more like BrainOverflow
Hello guys! It has been a while since I posted something. I was burnout however it's finished and i feel refreshed now!

I will explain my bggp3 entry in this post. This post includes how to prepare a simple harness and start an afl fuzz campaign, how to create portable fuzzing environment and root cause of the crash i found. I also have written a Dockerfile to experiment easily what I have explained and done here.
Table of Contents
- 1) Entry informations
- 2) Selecting a Target
- 3) My philosophy about finding bugs
- 4) Build BrainFlow with afl++
- 5) Build a program that uses BrainFlow
- 6) Prepare a Makefile
- 7) Spin up the fuzzer!
- 8) What happened?
- 9) Before finding the root cause
- 10) Fix The Issue
- 11) Conclusion
Entry informations
- ---BEGIN BGGP3 ENTRY---
- Name or handle: @echel0n
- Contact Info: https://t.me/echel0n
- Website, twitter, other online presence: twitter.com/echel0n_1881, devilinside.me
- Target Software and Version: BrainFlow 5.1.0
- Description of Target Software's Environment (Platform/OS, Setup Instructions, etc.): Linux, has Dockerfile
- Target File Type: TSV
- SHA256 Hash:636e13ecac749e4aaab6e9401ea311696b6ea2d20f399fb703e48d9eb32fef1c
- Brief Description of Crash: invalid check on data_handler::read_file and DataFilter::read_file lead to heap corruption
- Was this a new crash, or a known bug? A new crash
- Link to PoC video, screenshot, or console output, if any:
- Link to writeup, if any:
- CVE or other acknowledgement, if any: No
- File contents (base64 encoded please): MQkxCjkJMQkxCTIKMQo=
- ---END BGGP3 ENTRY---
- Score
- =---------------------------------------------=
- + 4082 payload
- + 1024 write-up
- + 0 authoring a patch (the developer authorized a patch before me after opening an issue)
- = 5106 points
- =---------------------------------------------=
Selecting A Target
I searched github for analyzer or parser that parses a data format both interesting and complex then found BrainFlow project. BrainFlow is a library intended to obtain, parse and analyze EEG, EMG, ECG and other kinds of data from biosensors. However, my target functionality is not that complex but it does it's work.
I quickly went to BrainFlow's documentation to learn more about it. I had concerns about not having a board to stream data into this library but documentation informs us BrainFlow has also dummy boards to create a valid stream. This is important to progress in the project because otherwise I would create valid structures manually and put them together to test the functionality of the library. Speaking of inputs, quick philosophy time!
My philosophy about finding bugs
- .
- ┌───────────────────────┐
- │ ▄▄▄▄▄ │
- │ ▄▄▄▄▄ │
- INPUT │ ▄▄▄▄▄ │ OUTPUTS
- ============> │ ▄▄▄▄▄ │=============>
- 0x2179656865....│ ▄▄▄▄▄ │..0x2169686875
- │ S Y S T E M ▄▄▄▄▄ │
- │ ▄▄▄▄▄ │
- │ ▄▄▄▄▄ │
- │ ▄▄▄▄▄ │
- │ ▄▄▄▄▄ │
- │ ▄▄▄▄▄ │
- │ ▄▄▄▄▄ │
- └───────────────────────┘
To generalize, all systems have inputs and outputs. The important thing is getting a great view of what kind of inputs that target system expects and how it accepts these. If the system fails to validate it's input to process, surely it will crash/break into pieces. Yeah, we call them as bugs. Moreover, when someone finds them and figures out how to take advantage of a bug, it becomes a security issue.
Build BrainFlow with afl++
Before diving into finding bugs and throwing gang signs to the community, we need to be sure that it compiles with current tool-chain. To learn if it will be compiled, i just did;
- $ git clone https://github.com/brainflow-dev/brainflow.git
- $ mkdir build && cd build
- $ cmake -DCMAKE_CXX_COMPILER=afl-clang-fast++ ..
- $ make -j16 Brainflow # after looking for available options in Makefile
I had crossed my fingers because sometimes projects do not like afl++ and newer llvm tool-chain, sometimes the target can be old and can't keep up with
current. I did not configure or enable other instrumentations other than defaults, there are many opportunities to find out what afl++ provides
but this post is not covering additional options
(for ex: laf-intel and REDQUEEN can help to bypass hard multi-byte comparisons).
To learn if instrumentation is applied to binary and it is compiled with correct tool-chain, I
usually (not proud of that) check with strings and it will be likely this;
- [afl++ brainflow] /app/brainflow/build (before_patch) # strings libBrainflow.a | grep __afl
- __afl_area_ptr
- __afl_area_ptr
- __afl_area_ptr
The instrumentation is very important because coverage guided fuzzers need feedback. If the library itself is not instrumented, even the greatest harness wont go through numerous paths without feedback.
Build a program that uses BrainFlow
To play with the library, I checked Code Samples section in the documentation especially C++ tab. While trying to understand the examples, I saw my first fuzzing target in C++ Read Write File example. Eureka!
- // https://brainflow.readthedocs.io/en/stable/Examples.html#id4
- ...
-
- int main (int argc, char *argv[])
- {
- BoardShim::enable_dev_board_logger ();
-
- struct BrainFlowInputParams params;
- int res = 0;
- int board_id = (int)BoardIds::SYNTHETIC_BOARD;
- // use synthetic board for demo
- BoardShim *board = new BoardShim (board_id, params);
-
- try
- {
- ...
- DataFilter::write_file (data, "test.csv", "w");
- BrainFlowArray<double, 2> restored_data = DataFilter::read_file ("test.csv");
- std::cout << "Restored data:" << std::endl << restored_data << std::endl;
- }
- catch (const BrainFlowException &err)
- {
- ...
- }
-
- delete board;
-
- return res;
- }
I was feeling lucky because my first primitive fuzzer can test this functionality and the snippet is easy to alter to a harness. Even it would find no bugs, I would run this harness and in the meantime I could learn more about it. However, it was enough to find a bug. I turned this snippet to something that gets a filename as an argument. On the other hand, I could manage to create a valid data in valid TSV format with dummy board. Thus, I got a valid seed to start with. Changed snippet below (full code is in brainflow-fuzz repository named as harness.cpp);
- ...
- ...
- int main (int argc, char *argv[])
- {
- int res = 0;
- try
- {
- // traditional file input
- BrainFlowArray<double, 2> data;
- BrainFlowArray<double, 2> restored_data = DataFilter::read_file (argv[1]);
- }
- catch (const BrainFlowException &err)
- {
- BoardShim::log_message ((int)LogLevels::LEVEL_ERROR, err.what ());
- res = err.exit_code;
- }
-
- return res;
- }
Prepare a Makefile
Not to manually write all files that the binary needs while compiling, i've created a rule in Makefile with trials and errors;
- ##########################
- ####################FUZZ##
-
- INCC = \
- $(shell find ../cpp_package/ -type d -name "inc" | sed s/^/-I/)
- INCCC = \
- $(shell find ../src/ -type d -name "inc" | sed s/^/-I/)
- INC = \
- $(shell find . -type f -name "*.cpp.o" | sed 's/^/ /')
-
- test_harness: harness.cpp
- afl-clang-fast++ -v harness.cpp $(INC) ./CMakeFiles/BoardController.dir/third_party/ant_neuro/eemagine/sdk/wrapper.cc.o -o harness $(INCC) $(INCCC) -I../third_party/json/
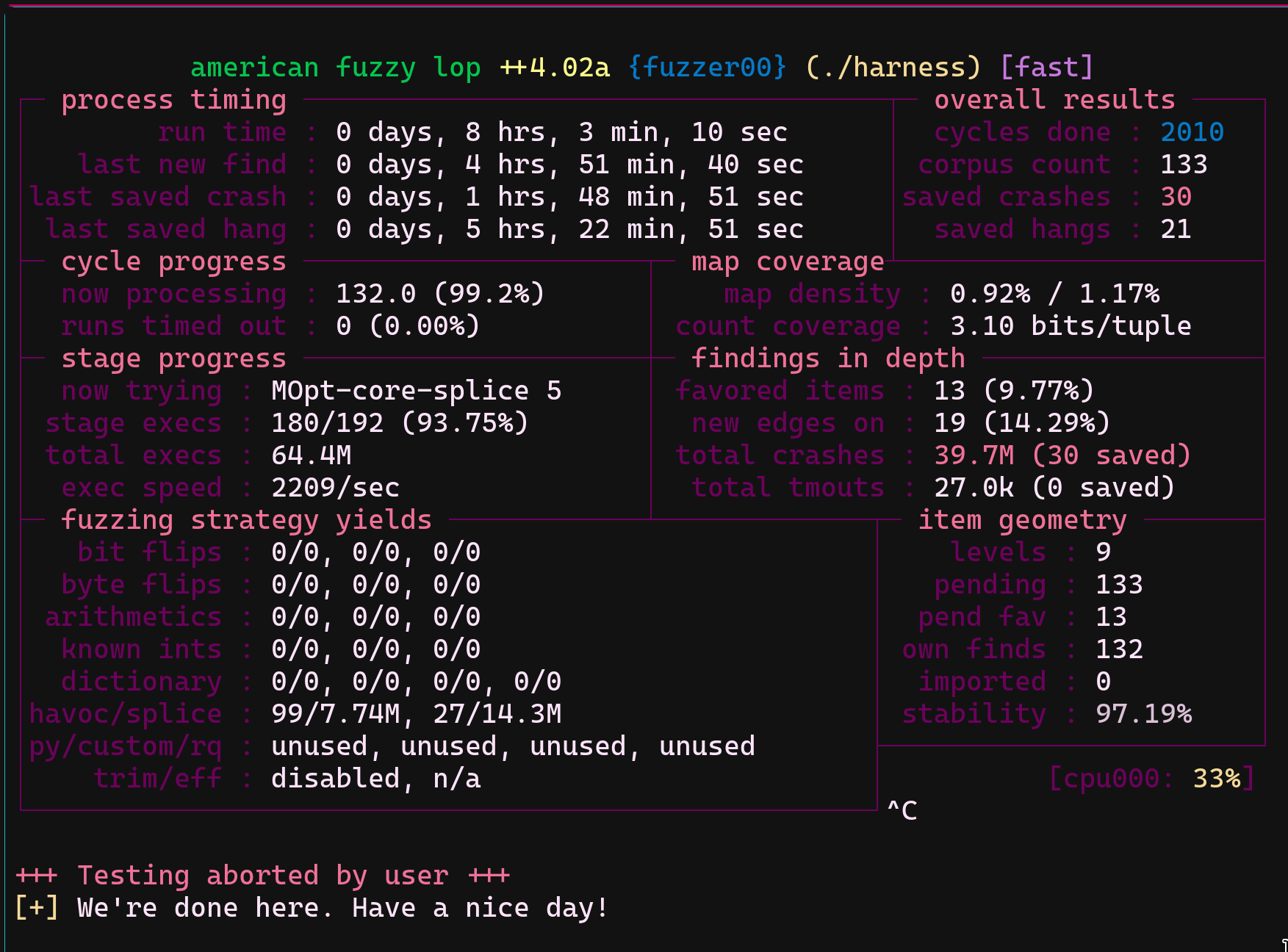
Spin up the fuzzer!
- $ make -j16 test_harness
- $ afl-fuzz -D -L0 -i samples/ -t 80 -o sync_dir -M fuzzer00 -- ./harness @@
What happened?
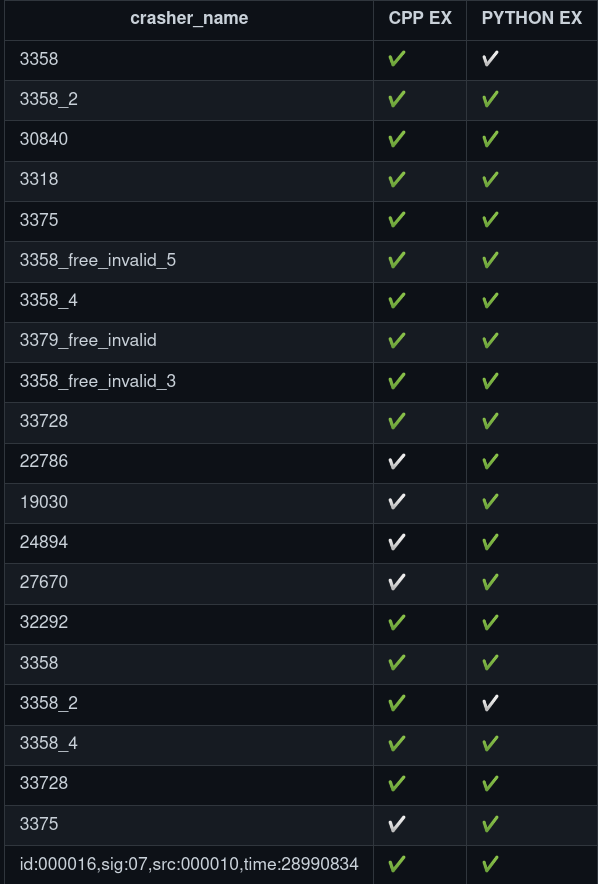
Whenever the fuzzer started, crashes started to show up immediately. Usually, when it acts like that, I assume that my harness is a trash. However, when I started to try crasher inputs manually, I found out some of them could manage to crash read_file function for real.


Some of them also crash when it is given through python too. (STATS.md) Interesting crashers inputs table is below;
(CPP EX:harness.cpp;PYTHON EX:brainoverflow.py)
Before finding the root cause
With quick analysis, I determined that at least 2 different bugs occur with these inputs. On the other hand, the produced inputs were way too big for bggp3 and at this point I was lost.
The corpus could be minimized with afl-cmin (usage ex: afl-cmin -i samples/ -o min -- ./harness @@), this tool also could reject redundant files if i had more than one.
(To modify the files, afl-tmin can be used too)
I was done with this laziness and started to delete the records and big numbers. While I was processing manually, I realized how dumb I am because these columns are nothing but just numbers. I spun up another fuzzer with an empty seed and continued to manually build the rows and columns. After a long time, I single-handedly proved infinite monkey theorem and found minimalist crash with a file that has inconsistent columns. 14 byte input below;
- $ xxd 14_bytes
- 00000000: 3109 310a 3909 3109 3109 320a 310a 1.1.9.1.1.2.1.
- $ cat 14_bytes # how it looks like
- 1 1
- 9 1 1 2
- 1
- $ ./harness crashers/14_bytes
- double free or corruption (out)
- Aborted (core dumped)
- // backtrace
- #0 0x0000555555799cf8 in std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_data (this=0x555555ad6920) at /usr/lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/basic_string.h:195
- #1 std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_is_local (this=0x555555ad6920) at /usr/lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/basic_string.h:230
- #2 std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_M_dispose (this=0x555555ad6920) at /usr/lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/basic_string.h:239
- #3 std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::~basic_string (this=0x555555ad6920) at /usr/lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/basic_string.h:672
- #4 std::_Destroy<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > (__pointer=0x555555ad6920) at /usr/lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/stl_construct.h:151
- #5 std::_Destroy_aux<false>::__destroy<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >*> (__first=0x555555ad6920, __last=<optimized out>) at /usr/lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/stl_construct.h:163
- #6 std::_Destroy<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >*> (__first=<optimized out>, __last=<optimized out>) at /usr/lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/stl_construct.h:195
- #7 std::_Destroy<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > (__first=<optimized out>, __last=<optimized out>) at /usr/lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/alloc_traits.h:854
- #8 std::vector<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::allocator<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >::~vector (this=0x7fffffffd270) at /usr/lib/gcc/x86_64-linux-gnu/11/../../../../include/c++/11/bits/stl_vector.h:680
- #9 read_file (data=0x555555ad58b0, num_rows=0x7fffffffe530, num_cols=0x7fffffffe52c, file_name=<optimized out>, num_elements=<optimized out>) at /app/brainflow/src/data_handler/data_handler.cpp:1015
- #10 0x00005555557eafa1 in DataFilter::read_file (file_name="14_byte") at /app/brainflow/cpp_package/src/data_filter.cpp:385
- #11 0x00005555555864e1 in main (argc=<optimized out>, argv=<optimized out>) at harness.cpp:27
- #12 0x00007ffff7829290 in ?? () from /usr/lib/libc.so.6
- #13 0x00007ffff782934a in __libc_start_main () from /usr/lib/libc.so.6
- #14 0x00005555555862d5 in _start ()
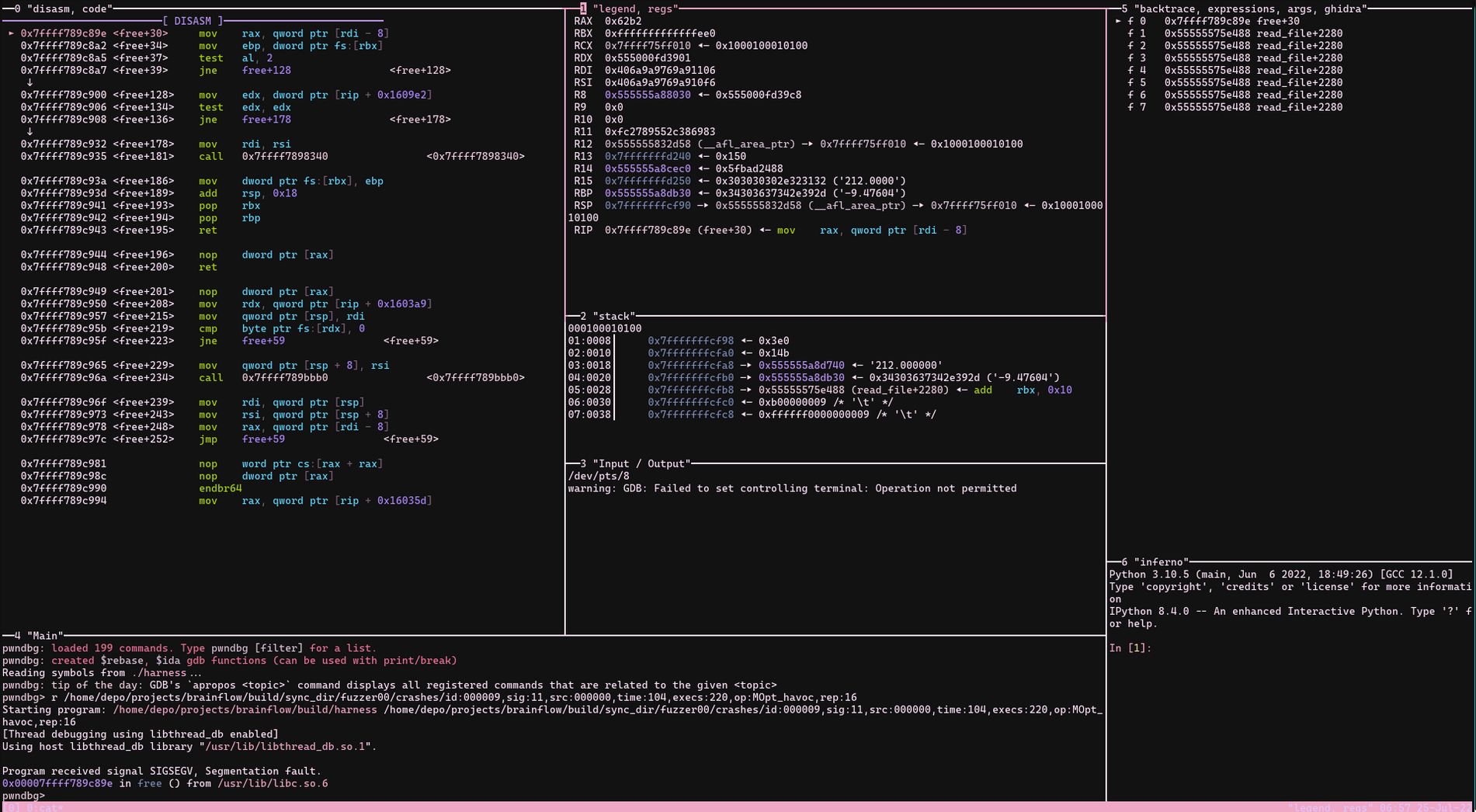
Finding the needle
I already decided that it must be related with inconsistency between first column count and others. I opened my gdb and source code (data_handler.cpp) and put them side by side then "ni" session was started!
- // https://github.com/brainflow-dev/brainflow/blob/master/cpp_package/src/data_filter.cpp
- // https://github.com/brainflow-dev/brainflow/blob/bfbcaa5afbb84522f5f2a52fba87ed13965cae49/src/data_handler/data_handler.cpp
- 1) DataFilter::read_file starts with get_num_elements_in_file function
- - ADHD version of get_num_elements_in_file function;
- 1) if file does not exist raise err
- 2) count newlines if there is no it is empty raise err
- 3) fseek to begin
- 4) read content with fgets into buf[4096] (umm can be another vuln?)
- 5) separate elements with tab character add put all elements into splitted vector repeat for lines
- 6) set *num_elements = (int)splitted.size () * total_rows; // inconsistent row elem size
- 2) max_elements became first splitted.size * total_rows = 6
- 3) double *data_linear = new double[6];
- 3) memset (data_linear, 0, sizeof (double) * max_elements); // n = (0x8)*(0x2)(0x3) = 0x30
- 4) call read_file (data_linear, &num_rows, &num_cols, file_name.c_str (), max_elements)
- - ADHD version of read_file (double *data, int *num_rows, int *num_cols, const char *file_name, int num_elements)
- 1) check if num_elements > 0 if it is raise err
- 2) if file does not exist raise err
- 3) count rows again increment total_rows
- 4) fseek to begin
- 5) read content with fgets into buf[4096]
- 6) separate elements with tab character add put all elements into splitted vector again
- 7) total_cols = (int)splitted.size (); // will be inconsistent last row elem size and will lead to corruption of memory.
- 8) for (int i = 0; i < total_cols; i++)
- data[i * total_rows + current_row] = std::stod (splitted[i]); // str to double
- cur_pos++
- if cur_pos < (max_elements - 1) stop
- 9) current_row++;
- TLDR; In for (int i = 0; i < total_cols; i++) loop, it will be messed up
Fix The Issue
A lot of fix are available, it can be applied to total_cols line or before. At this point, it was early in the morning and I hadn't sleep at night and stopped here. So, I decided to open an issue and show my results to the developer, while thinking that it would take time to analyze these crashes. However, the developer acted quickly (well done! 👏 ), had fixed the lines until I woke up.
- if ((total_cols != 0) && (total_cols != (int)splitted.size ())) // if it's changed to something else raise err
- {
- data_logger->error ("some rows have more cols than others, invalid input file");
- fclose (fp);
- return (int)BrainFlowExitCodes::INVALID_ARGUMENTS_ERROR;
- }
- total_cols = (int)splitted.size ();
Conclusion
After all, I feel happy to help open-source community and got something for bggp3. Actually, I wanted to fuzz a target requires more work but I may have no
time to complete it in time. I hope you guys enjoyed it and easily followed the write-up.
Thanks to @netspooky and his encouragement.
To reproduce follow these steps;
(In brainflow-fuzz repository there are more crasher inputs to try)
- $ git clone https://github.com/echel0nn/brainflow-fuzz.git
- $ chmod +x build_and_start_docker.sh
- $ ./build_and_start_docker.sh # dont forget to add yourself to docker group
- [afl++ brainflow] /app/brainflow/build (before_patch) # ./harness crashers/14_bytes
- double free or corruption (out)
- Aborted (core dumped)
- [afl++ brainflow] /app/brainflow/build (before_patch) # ./fuzz.sh # to fuzz the target
- [afl++ brainflow] /app/brainflow/build (before_patch) # python brainoverflow.py crashers/1168_python_crasher # get bonus sigsegv for fun, payload length is 1168
- crashers/1168_python_crasher
- 0 1
- 0 2222.0 2.0
- 1 3223.0 0.0
- 2 2.0 22.0
- 3 22.0 0.0
- 4 222.0 0.0
- 5 0.0 0.0
- 6 22.0 0.0
- 7 223.0 0.0
- 8 3.0 22.0
- 9 2.0 22.0
- Segmentation fault (core dumped)
Thank you for reading my write-up! Have a nice day absolute legends!